2.core内核实例、IK分词器、Solr(单机、集群) |
您所在的位置:网站首页 › solr core › 2.core内核实例、IK分词器、Solr(单机、集群) |
2.core内核实例、IK分词器、Solr(单机、集群)
|
目录
1. Apache Solr介绍、下载及其安装 2. core内核实例、IK分词器、Solr(单机、集群) 3. Solr基本命令(启动、停止、系统信息) 4. Solr的solrconfig.xml配置与managed.schema模式 5. Solr Admin UI操作(XML、JSON 新增|修改|删除|查询 索引) 6. Solr配置DataImport导入索引数据、IK分词查询 7. Java中使用Solr,历史版本(7.0.0之后、5.0.0~6.6.6、4.10.4之前) 8. 传统Spring整合Solr 9. Spring Boot整合Solr core内核实例、IK分词器、Solr(单机、集群) 目录core内核实例、IK分词器、Solr(单机、集群)创建一个core内核实例(两种)1.使用solr create -c name命令2.直接使用Admin UI页面创建一个core 分词器(IKAnalyzer)IK下载 单机版Solr1.Solr安装目录下放入jar包2.配置Solr的managed-schema,添加ik分词器3.启动Solr服务测试分词器 Solr-Cloud(集群)1.Solr安装目录下放入jar包2.ik.conf及dynamicdic.txt放入solr配置文件夹3.配置Solr的managed-schema,添加ik分词器4.测试分词5.测试动态词典 core内核实例、IK分词器、Solr(单机、集群) 创建一个core内核实例(两种)简单说core就是solr的一个实例,一个solr服务下可以有多个core,每个core下都有自己的索引库和与之相应的配置文件,所以在操作solr创建索引之前要创建一个core,因为索引都存在core下面 1.使用solr create -c name命令创建一个内核才能进行索引和搜索 创建一个使用数据驱动架构的核心,该架构会在将文档添加到索引时尝试猜测正确的字段类型 在bin目录下执行"solr create –c name"。创建一个core,默认创建出来的位置如下图 命令描述bin/solr create -c 创建一个内核bin/solr create -help查看用于创建新核心的所有可用选项
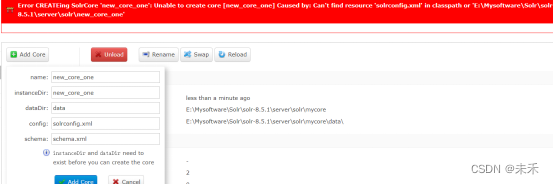
对于报错问题。原因缺少solrconfig.xml配置文件
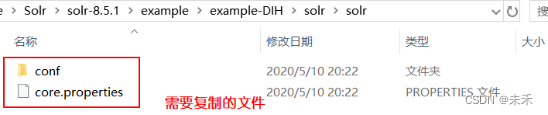
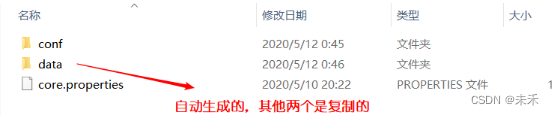
解决:将example\example-DIH\solr\solr下的文件,复制到new_core_one文件中
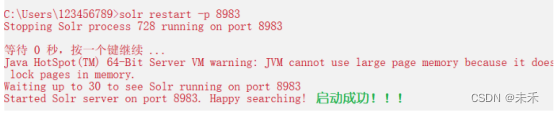
接下来在之前启动的cmd窗口重启一下solr服务,在控制台输入以下命令 solr restart -p 8983
访问Admin UI后会自动生成data文件集 IKAnalyzer是一个开源的,基于Java语言开发的轻量级的中文分词工具包 IK下载Solr 8x需要下载新版本的。以前旧版本的2012不支持有问题 GitHub地址:https://github.com/magese/ik-analyzer-solr com.github.magese ik-analyzer 8.3.0 单机版Solr 1.Solr安装目录下放入jar包将jar包放入Solr服务的Jetty或Tomcat的webapp/WEB-INF/lib/目录下。也就是Solr安装目录下的\server\solr-webapp\webapp\WEB-INF\lib下面
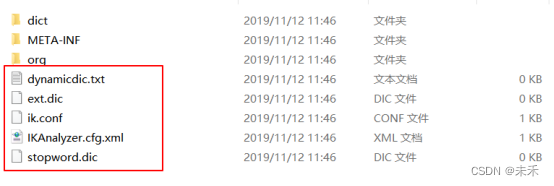
将resources目录下的5个配置文件放入Solr服务的Jetty或Tomcat的webapp/WEB-INF/classes/目录下 ①IKAnalyzer.cfg.xml ②ext.dic ③stopword.dic ④ik.conf ⑤dynamicdic.txt 在Jar包里面存在这几个文件,所以不需要上面配置 文件说明 (1)IKAnalyzer.cfg.xml配置文件 名称类型描述默认use_main_dictboolean是否使用默认主词典trueext_dictString扩展词典文件名称,多个用分号隔开ext.dic;ext_stopwordsString停用词典文件名称,多个用分号隔开stopword.dic;(2)ik.conf文件 files = dynamicdic.txt lastupdate = 0 配置描述files为动态字典列表,可以设置多个字典表,用逗号进行分隔,替换动态字典表为dynamicdic.txtlastupdate默认值0,每次对动态字典表修改后请+1,不然不会将字典表中新的歌词添加到内存中。采用lastupdate的int类型,不支持替换,如果使用替代的朋友可以把源码的中int改成long即可; 2018-08-23已将源码中lastUpdate对划线long类型,现可以用时间戳了(3)dynamicdic.txt 为动态词典 在此文件配置的短语不需重启服务即可加载进内存中。以#开头的单词注释注释,将不会加载到内存中 2.配置Solr的managed-schema,添加ik分词器在创建的croe实例里,修改managed-schema配置文件,在文件里增加以下代码 3.启动Solr服务测试分词器 solr start
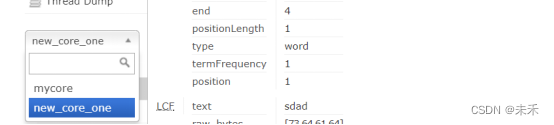
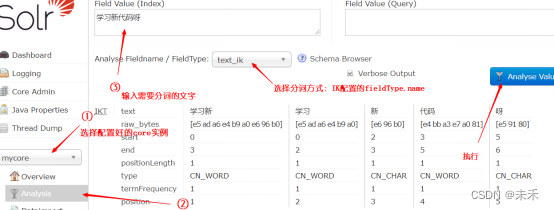
因为Solr-Cloud中的配置文件是交由zookeeper进行管理的,所以为了方便更新动态词典,所以也要将动态词典文件上传至zookeeper中,目录与solr的配置文件目录一致 注意:因为zookeeper中的配置文件大小不能超过1m,当词典列表过多时,需将词典文件切分成多个 1.Solr安装目录下放入jar包将jar包放入每台服务器的Solr服务的Jetty或Tomcat的webapp/WEB-INF/lib/目录下; 将resources目录下的IKAnalyzer.cfg.xml、ext.dic、stopword.dic放入solr服务的Jetty或Tomcat的webapp/WEB-INF/classes/目录下; ① IKAnalyzer.cfg.xml(IK默认的配置文件,用于配置自带的扩展词典及停用词典) ② ext.dic (默认的扩展词典) ③ stopword.dic(默认的停词词典) 注意:与单机版不同,ik.conf及dynamicdic.txt请不要放在classes目录下 2.ik.conf及dynamicdic.txt放入solr配置文件夹将resources目录下的ik.conf及dynamicdic.txt放入solr配置文件夹中,与solr的managed-schema文件同目录中 ①ik.conf(动态词典配置文件) 配置描述files动态词典列表,可以设置多个词典表,用逗号进行分隔,默认动态词典表为dynamicdic.txtlastupdate默认值为0,每次对动态词典表修改后请修改该值,必须大于上次的值,不然不会将词典表中新的词语添加到内存中② dynamicdic.txt 默认的动态词典,在此文件配置的词语不需重启服务即可加载进内存中。以#开头的词语视为注释,将不会加载到内存中 3.配置Solr的managed-schema,添加ik分词器schema是用来告诉solr如何建立索引的,它的配置围绕着一个schema配置文件,这个配置文件决定着solr如何建立索引,每个字段的数据类型,分词方式等,老版本的schema配置文件的名字叫做schema.xml他的配置方式就是手工编辑,但是现在新版本的schema配置文件的名字叫做managed-schema,他的配置方式不再是用手工编辑而是使用schemaAPI来配置,官方给出的解释是使用schemaAPI修改managed-schema内容后不需要重新加载core或者重启solr更适合在生产环境下维护,如果使用手工编辑的方式更改配置不进行重加载core有可能会造成配置丢失 将配置文件上传至zookeeper中,首次使用请重启服务或reload Collection 4.测试分词此时的动态词典文件为空 ;配置文件lastupdate为0 测试分词 5.测试动态词典增加动态词典词语并上传至zookeeper ;修改配置文件并上传至zookeeper 测试分词 |

【本文地址】
今日新闻 |
推荐新闻 |